Note
Go to the end to download the full example code. or to run this example in your browser via Binder
Comprehensive Error Correction Codes Benchmark
This example demonstrates a comprehensive benchmark for Forward Error Correction (FEC) codes using the Kaira benchmarking system. It evaluates multiple ECC algorithms across different parameters and provides detailed performance comparison.
The comprehensive ECC benchmark includes:
Multiple error correction codes (Hamming, BCH, Golay, Repetition, Single Parity Check)
Block Error Rate (BLER) and Bit Error Rate (BER) evaluation
Coding gain analysis
Error correction capability evaluation
Comparison across different code rates and block lengths
Note: Individual benchmarks use only repetition codes (the only code type currently supported by ChannelCodingBenchmark), while the comprehensive benchmark tests all available ECC implementations directly using the FEC encoder/decoder classes.
Setting up the Environment
First, let’s import the necessary modules for comprehensive ECC benchmarking.
from pathlib import Path
from typing import Any, Dict
import matplotlib.pyplot as plt
import numpy as np
import torch
from kaira.benchmarks import (
BenchmarkConfig,
BenchmarkSuite,
StandardRunner,
create_benchmark,
register_benchmark,
)
from kaira.benchmarks.base import CommunicationBenchmark
from kaira.benchmarks.metrics import StandardMetrics
from kaira.channels.analog import AWGNChannel
from kaira.models.fec.decoders import (
BeliefPropagationDecoder,
BruteForceMLDecoder,
SuccessiveCancellationDecoder,
SyndromeLookupDecoder,
)
from kaira.models.fec.encoders import (
BCHCodeEncoder,
GolayCodeEncoder,
HammingCodeEncoder,
LDPCCodeEncoder,
PolarCodeEncoder,
RepetitionCodeEncoder,
SingleParityCheckCodeEncoder,
)
from kaira.modulations.psk import BPSKDemodulator, BPSKModulator
from kaira.utils import snr_to_noise_power
# Set random seed for reproducibility
np.random.seed(42)
torch.manual_seed(42)
<torch._C.Generator object at 0x7f19765aa410>
Creating the Comprehensive ECC Benchmark
Let’s create a comprehensive benchmark that evaluates multiple ECC algorithms.
@register_benchmark("comprehensive_ecc")
class ComprehensiveECCBenchmark(CommunicationBenchmark):
"""Comprehensive benchmark for error correction codes."""
def __init__(self, **kwargs):
"""Initialize comprehensive ECC benchmark."""
super().__init__(name="Comprehensive ECC Benchmark", description="Comprehensive evaluation of error correction codes")
def setup(self, **kwargs):
"""Setup benchmark parameters."""
super().setup(**kwargs)
self.num_bits = kwargs.get("num_bits", 1000)
self.num_trials = kwargs.get("num_trials", 1000)
self.max_errors = kwargs.get("max_errors", 10)
self.snr_range = kwargs.get("snr_range", list(range(-4, 8, 2)))
# Define ECC configurations to test
self.ecc_configs = [
{"name": "Hamming(7,4)", "encoder": HammingCodeEncoder, "decoder": SyndromeLookupDecoder, "params": {"mu": 3}, "block_length": 7, "info_length": 4, "min_distance": 3, "error_correction_capability": 1},
{"name": "Hamming(15,11)", "encoder": HammingCodeEncoder, "decoder": SyndromeLookupDecoder, "params": {"mu": 4}, "block_length": 15, "info_length": 11, "min_distance": 3, "error_correction_capability": 1},
{"name": "BCH(15,7)", "encoder": BCHCodeEncoder, "decoder": SyndromeLookupDecoder, "params": {"mu": 4, "delta": 5}, "block_length": 15, "info_length": 7, "min_distance": 5, "error_correction_capability": 2},
{"name": "BCH(31,16)", "encoder": BCHCodeEncoder, "decoder": BruteForceMLDecoder, "params": {"mu": 5, "delta": 7}, "block_length": 31, "info_length": 16, "min_distance": 7, "error_correction_capability": 3},
{"name": "Golay(23,12)", "encoder": GolayCodeEncoder, "decoder": BruteForceMLDecoder, "params": {"extended": False}, "block_length": 23, "info_length": 12, "min_distance": 7, "error_correction_capability": 3},
{"name": "Extended Golay(24,12)", "encoder": GolayCodeEncoder, "decoder": BruteForceMLDecoder, "params": {"extended": True}, "block_length": 24, "info_length": 12, "min_distance": 8, "error_correction_capability": 3},
{"name": "Repetition(3,1)", "encoder": RepetitionCodeEncoder, "decoder": BruteForceMLDecoder, "params": {"repetition_factor": 3}, "block_length": 3, "info_length": 1, "min_distance": 3, "error_correction_capability": 1},
{"name": "Repetition(5,1)", "encoder": RepetitionCodeEncoder, "decoder": BruteForceMLDecoder, "params": {"repetition_factor": 5}, "block_length": 5, "info_length": 1, "min_distance": 5, "error_correction_capability": 2},
{"name": "Single Parity Check(8,7)", "encoder": SingleParityCheckCodeEncoder, "decoder": BruteForceMLDecoder, "params": {"dimension": 7}, "block_length": 8, "info_length": 7, "min_distance": 2, "error_correction_capability": 0}, # Detection only
{
"name": "LDPC(128,64) - RPTU",
"encoder": LDPCCodeEncoder,
"decoder": BeliefPropagationDecoder,
"params": {"rptu_database": True, "code_length": 128, "code_dimension": 64},
"block_length": 128,
"info_length": 64,
"min_distance": 4, # Approximate for LDPC
"error_correction_capability": 2, # Approximate
"use_soft_decoding": True,
},
{
"name": "LDPC(256,128) - RPTU",
"encoder": LDPCCodeEncoder,
"decoder": BeliefPropagationDecoder,
"params": {"rptu_database": True, "code_length": 256, "code_dimension": 128},
"block_length": 256,
"info_length": 128,
"min_distance": 4, # Approximate for LDPC
"error_correction_capability": 2, # Approximate
"use_soft_decoding": True,
},
{
"name": "Polar(32,16)",
"encoder": PolarCodeEncoder,
"decoder": SuccessiveCancellationDecoder,
"params": {"code_dimension": 16, "code_length": 32},
"block_length": 32,
"info_length": 16,
"min_distance": 4, # Approximate for Polar
"error_correction_capability": 2, # Approximate
"use_soft_decoding": True,
},
{
"name": "Polar(64,32)",
"encoder": PolarCodeEncoder,
"decoder": SuccessiveCancellationDecoder,
"params": {"code_dimension": 32, "code_length": 64},
"block_length": 64,
"info_length": 32,
"min_distance": 4, # Approximate for Polar
"error_correction_capability": 2, # Approximate
"use_soft_decoding": True,
},
]
def _generate_random_errors(self, codeword_length: int, num_errors: int) -> torch.Tensor:
"""Generate random error pattern."""
error_pattern = torch.zeros(codeword_length, dtype=torch.float32, device=self.device)
if num_errors > 0:
error_positions = torch.randperm(codeword_length)[:num_errors]
error_pattern[error_positions] = 1
return error_pattern
def _evaluate_error_correction_capability(self, config: dict) -> dict:
"""Evaluate error correction capability for a specific code."""
encoder_class = config["encoder"]
decoder_class = config["decoder"]
# Initialize encoder and decoder
try:
encoder = encoder_class(**config["params"])
# Handle different decoder types
if decoder_class == BeliefPropagationDecoder:
decoder = decoder_class(encoder=encoder, bp_iters=10)
elif decoder_class == SuccessiveCancellationDecoder:
decoder = decoder_class(encoder=encoder)
else:
# Traditional decoders that take encoder instance
decoder = decoder_class(encoder=encoder)
except Exception as e:
print(f"Failed to initialize {config['name']}: {e}")
return {"success": False, "error": str(e), "error_rates": [], "correction_rates": []}
results: Dict[str, Any] = {"success": True, "error_rates": [], "correction_rates": [], "detection_rates": [], "block_error_rates": [], "bit_error_rates": []}
# Test different numbers of errors
for num_errors in range(self.max_errors + 1):
correct_corrections = 0
correct_detections = 0
total_block_errors = 0
total_bit_errors = 0
total_bits = 0
for _ in range(self.num_trials):
# Generate random information bits - use float32 for consistency
info_bits = torch.randint(0, 2, (config["info_length"],), dtype=torch.float32, device=self.device)
# Encode - use forward method (__call__)
try:
# Handle Polar code which expects 2D input
if config["encoder"] == PolarCodeEncoder:
input_bits = info_bits.unsqueeze(0) # Add batch dimension
codeword = encoder(input_bits).squeeze(0) # Remove batch dimension
else:
codeword = encoder(info_bits)
except (RuntimeError, ValueError, TypeError, AttributeError, IndexError):
# Handle encoding failures (dimension mismatches, invalid parameters, etc.)
continue
# Add errors
error_pattern = self._generate_random_errors(len(codeword), num_errors)
received = (codeword + error_pattern.float()) % 2
# Decode - use forward method (__call__)
try:
# Handle different decoder input requirements
if config.get("use_soft_decoding", False):
# Use proper BPSK modulation/demodulation pipeline for soft decoding
modulator = BPSKModulator(complex_output=False)
demodulator = BPSKDemodulator()
# Step 1: Modulate codeword to bipolar symbols (-1, +1)
bipolar_symbols = modulator(codeword.unsqueeze(0)).squeeze(0) # Add/remove batch dim
# Step 2: Simulate channel with controlled errors
# Use SNR that allows num_errors to be correctable but challenging
target_snr_db = 2.0 # Moderate SNR for capability testing
noise_power = snr_to_noise_power(1.0, target_snr_db)
channel = AWGNChannel(avg_noise_power=noise_power)
# Apply channel noise
received_soft = channel(bipolar_symbols.unsqueeze(0)).squeeze(0) # Add/remove batch dim
# Step 3: Demodulate to get proper LLRs
llr_received = demodulator(received_soft.unsqueeze(0), noise_var=noise_power).squeeze(0)
# Step 4: Decode using proper LLRs
input_received = llr_received.unsqueeze(0) # Add batch dimension for decoder
decoded_info = decoder(input_received).squeeze(0) # Remove batch dimension
else:
# Hard decoding for traditional codes
decoded_info = decoder(received)
# Check if decoding was successful
if torch.equal(info_bits, decoded_info):
correct_corrections += 1
else:
# Count bit errors
bit_errors = torch.sum(info_bits != decoded_info).item()
total_bit_errors += bit_errors
total_block_errors += 1
except Exception:
# Decoding failed - count as detection if within capability
if num_errors <= config["error_correction_capability"]:
pass # Should have been corrected
else:
correct_detections += 1
total_bits += config["info_length"]
# Calculate rates
correction_rate = correct_corrections / self.num_trials if self.num_trials > 0 else 0
detection_rate = correct_detections / self.num_trials if self.num_trials > 0 else 0
block_error_rate = total_block_errors / self.num_trials if self.num_trials > 0 else 0
bit_error_rate = total_bit_errors / total_bits if total_bits > 0 else 0
results["correction_rates"].append(correction_rate)
results["detection_rates"].append(detection_rate)
results["block_error_rates"].append(block_error_rate)
results["bit_error_rates"].append(bit_error_rate)
return results
def _evaluate_snr_performance(self, config: dict) -> dict:
"""Evaluate BER and BLER performance over SNR range."""
encoder_class = config["encoder"]
decoder_class = config["decoder"]
try:
encoder = encoder_class(**config["params"])
# Handle different decoder types
if decoder_class == BeliefPropagationDecoder:
decoder = decoder_class(encoder=encoder, bp_iters=10)
elif decoder_class == SuccessiveCancellationDecoder:
decoder = decoder_class(encoder=encoder)
else:
decoder = decoder_class(encoder=encoder)
except Exception as e:
return {"success": False, "error": str(e), "ber_coded": [], "ber_uncoded": [], "bler_coded": [], "bler_uncoded": [], "coding_gain": []}
ber_coded = []
ber_uncoded = []
bler_coded = []
bler_uncoded = []
coding_gain = []
for snr_db in self.snr_range:
# Generate information bits - use float32 for consistency
num_info_bits = (self.num_bits // config["info_length"]) * config["info_length"]
info_bits = torch.randint(0, 2, (num_info_bits,), dtype=torch.float32, device=self.device)
# Reshape for block processing
info_blocks = info_bits.reshape(-1, config["info_length"])
# Encode all blocks
coded_blocks = []
for block in info_blocks:
try:
# Handle Polar code which expects 2D input
if config["encoder"] == PolarCodeEncoder:
input_block = block.unsqueeze(0) # Add batch dimension
coded_block = encoder(input_block).squeeze(0) # Remove batch dimension
coded_blocks.append(coded_block)
else:
coded_blocks.append(encoder(block))
except (RuntimeError, ValueError, TypeError, AttributeError, IndexError):
# Skip failed blocks (dimension mismatches, invalid parameters, etc.)
continue
if not coded_blocks:
ber_coded.append(1.0)
ber_uncoded.append(1.0)
bler_coded.append(1.0)
bler_uncoded.append(1.0)
coding_gain.append(0.0)
continue
coded_bits = torch.cat(coded_blocks)
# BPSK modulation
coded_symbols = 2 * coded_bits.float() - 1
# For uncoded, use the same number of info bits as we have coded blocks
num_uncoded_bits = len(info_blocks) * config["info_length"]
uncoded_bits = info_bits[:num_uncoded_bits]
uncoded_symbols = 2 * uncoded_bits.float() - 1
# Add AWGN - SNR is per information bit (Eb/N0)
# For fair comparison, both coded and uncoded should use same Eb/N0
snr_linear = 10 ** (snr_db / 10)
# Both systems use same SNR (same Eb/N0)
coded_snr_linear = snr_linear
uncoded_snr_linear = snr_linear
# Noise calculation
coded_noise_std = torch.sqrt(torch.tensor(1 / (2 * coded_snr_linear), device=self.device))
uncoded_noise_std = torch.sqrt(torch.tensor(1 / (2 * uncoded_snr_linear), device=self.device))
coded_received = coded_symbols + coded_noise_std * torch.randn_like(coded_symbols)
uncoded_received = uncoded_symbols + uncoded_noise_std * torch.randn_like(uncoded_symbols)
# Handle modern codes (LDPC, Polar) that need soft decoding
if config["decoder"] in [BeliefPropagationDecoder, SuccessiveCancellationDecoder]:
# Use proper BPSK modulation/demodulation pipeline for soft decoding
modulator = BPSKModulator(complex_output=False)
demodulator = BPSKDemodulator()
coded_received_blocks = coded_bits.reshape(-1, config["block_length"])
decoded_blocks = []
for block in coded_received_blocks:
try:
# Step 1: Modulate codeword to bipolar symbols
bipolar_symbols = modulator(block.unsqueeze(0)).squeeze(0)
# Step 2: Add AWGN noise
noise_power = snr_to_noise_power(1.0, snr_db)
channel = AWGNChannel(avg_noise_power=noise_power)
received_soft = channel(bipolar_symbols.unsqueeze(0)).squeeze(0)
# Step 3: Demodulate to proper LLRs
llr_block = demodulator(received_soft.unsqueeze(0), noise_var=noise_power).squeeze(0)
# Step 4: Decode using proper LLRs
input_block = llr_block.unsqueeze(0) # Add batch dimension
decoded_block = decoder(input_block).squeeze(0) # Remove batch dimension
decoded_blocks.append(decoded_block)
except Exception:
# For failed decoding, generate random bits (worst case)
decoded_blocks.append(torch.randint(0, 2, (config["info_length"],), dtype=torch.float32, device=self.device))
else:
# Hard decision for traditional codes
coded_hard = (coded_received > 0).float()
uncoded_hard = (uncoded_received > 0).float()
# Decode coded bits
coded_hard_blocks = coded_hard.reshape(-1, config["block_length"])
decoded_blocks = []
for block in coded_hard_blocks:
try:
decoded_blocks.append(decoder(block))
except Exception:
# For failed decoding, generate random bits (worst case)
decoded_blocks.append(torch.randint(0, 2, (config["info_length"],), dtype=torch.float32, device=self.device))
# Calculate metrics
if decoded_blocks:
decoded_bits = torch.cat(decoded_blocks)
# Calculate coded BER and BLER
original_info_bits = info_bits[: len(decoded_blocks) * config["info_length"]]
ber_c = StandardMetrics.bit_error_rate(original_info_bits, decoded_bits)
ber_coded.append(float(ber_c))
# Calculate BLER (Block Error Rate)
block_errors = 0
for i, block in enumerate(decoded_blocks):
start_idx = i * config["info_length"]
end_idx = start_idx + config["info_length"]
original_block = original_info_bits[start_idx:end_idx]
if not torch.equal(original_block, block):
block_errors += 1
bler_c = block_errors / len(decoded_blocks) if len(decoded_blocks) > 0 else 1.0
bler_coded.append(bler_c)
else:
ber_coded.append(1.0)
bler_coded.append(1.0)
# Uncoded BER and BLER - Hard decision for uncoded case
uncoded_hard = (uncoded_received > 0).float()
ber_u = StandardMetrics.bit_error_rate(uncoded_bits, uncoded_hard)
ber_uncoded.append(float(ber_u))
# Uncoded BLER - treat each info_length block as a block
uncoded_blocks = uncoded_bits.reshape(-1, config["info_length"])
uncoded_hard_blocks = uncoded_hard.reshape(-1, config["info_length"])
uncoded_block_errors = 0
for orig_block, hard_block in zip(uncoded_blocks, uncoded_hard_blocks):
if not torch.equal(orig_block, hard_block):
uncoded_block_errors += 1
bler_u = uncoded_block_errors / len(uncoded_blocks) if len(uncoded_blocks) > 0 else 1.0
bler_uncoded.append(bler_u)
# Calculate coding gain
if ber_u > 0 and ber_c > 0 and ber_c < ber_u:
gain = 10 * torch.log10(torch.tensor(ber_u / ber_c)).item()
coding_gain.append(gain)
elif ber_u > 0 and ber_c == 0:
# Perfect coding - use a high but finite gain
coding_gain.append(30.0) # High coding gain for perfect correction
else:
coding_gain.append(0.0)
return {"success": True, "ber_coded": ber_coded, "ber_uncoded": ber_uncoded, "bler_coded": bler_coded, "bler_uncoded": bler_uncoded, "coding_gain": coding_gain}
def run(self, **kwargs) -> dict:
"""Run comprehensive ECC benchmark."""
results: Dict[str, Any] = {"success": True, "configurations": [], "error_correction_results": {}, "snr_performance_results": {}, "summary": {}}
print(f"Running comprehensive ECC benchmark with {len(self.ecc_configs)} configurations...")
for i, config in enumerate(self.ecc_configs):
print(f"Evaluating {config['name']} ({i+1}/{len(self.ecc_configs)})...")
# Store configuration info
config_info = {"name": config["name"], "block_length": config["block_length"], "info_length": config["info_length"], "code_rate": config["info_length"] / config["block_length"], "min_distance": config["min_distance"], "error_correction_capability": config["error_correction_capability"]}
results["configurations"].append(config_info)
# Evaluate error correction capability
ec_results = self._evaluate_error_correction_capability(config)
results["error_correction_results"][config["name"]] = ec_results
# Evaluate SNR performance
snr_results = self._evaluate_snr_performance(config)
results["snr_performance_results"][config["name"]] = snr_results
return results
Running Individual ECC Algorithms
Let’s start by running individual ECC algorithms to understand their performance.
def run_individual_ecc_benchmarks():
"""Run individual ECC benchmarks."""
print("Running Individual ECC Benchmarks...")
# Configuration for individual tests - only using codes supported by ChannelCodingBenchmark
configs = [("Repetition Code (Rate 1/3)", "repetition", 1 / 3), ("Repetition Code (Rate 1/5)", "repetition", 1 / 5), ("Repetition Code (Rate 1/7)", "repetition", 1 / 7)]
results = {}
for name, code_type, code_rate in configs:
print(f"\nTesting {name}...")
# Create channel coding benchmark for this specific code
benchmark = create_benchmark("channel_coding", code_type=code_type, code_rate=code_rate)
# Configure benchmark
config = BenchmarkConfig(name=f"{name}_benchmark", snr_range=list(range(-2, 8, 2)), verbose=False)
config.update(num_bits=5000)
# Run benchmark
runner = StandardRunner(verbose=False)
result = runner.run_benchmark(benchmark, **config.to_dict())
results[name] = result
if result.metrics["success"]:
print(f" Average coding gain: {result.metrics.get('average_coding_gain', 0):.2f} dB")
else:
print(" Benchmark failed")
return results
Running Comprehensive ECC Benchmark
Now let’s run our comprehensive benchmark that evaluates multiple aspects.
def run_comprehensive_ecc_benchmark():
"""Run the comprehensive ECC benchmark."""
print("Running Comprehensive ECC Benchmark...")
# Create comprehensive benchmark
benchmark = create_benchmark("comprehensive_ecc")
# Configure benchmark
config = BenchmarkConfig(name="comprehensive_ecc_evaluation", snr_range=list(range(-4, 8, 2)), num_trials=50, verbose=True)
config.update(num_bits=1000, max_errors=10)
# Run benchmark
runner = StandardRunner(verbose=True)
result = runner.run_benchmark(benchmark, **config.to_dict())
return result
Performance Comparison and Visualization
Let’s create comprehensive visualizations of ECC performance.
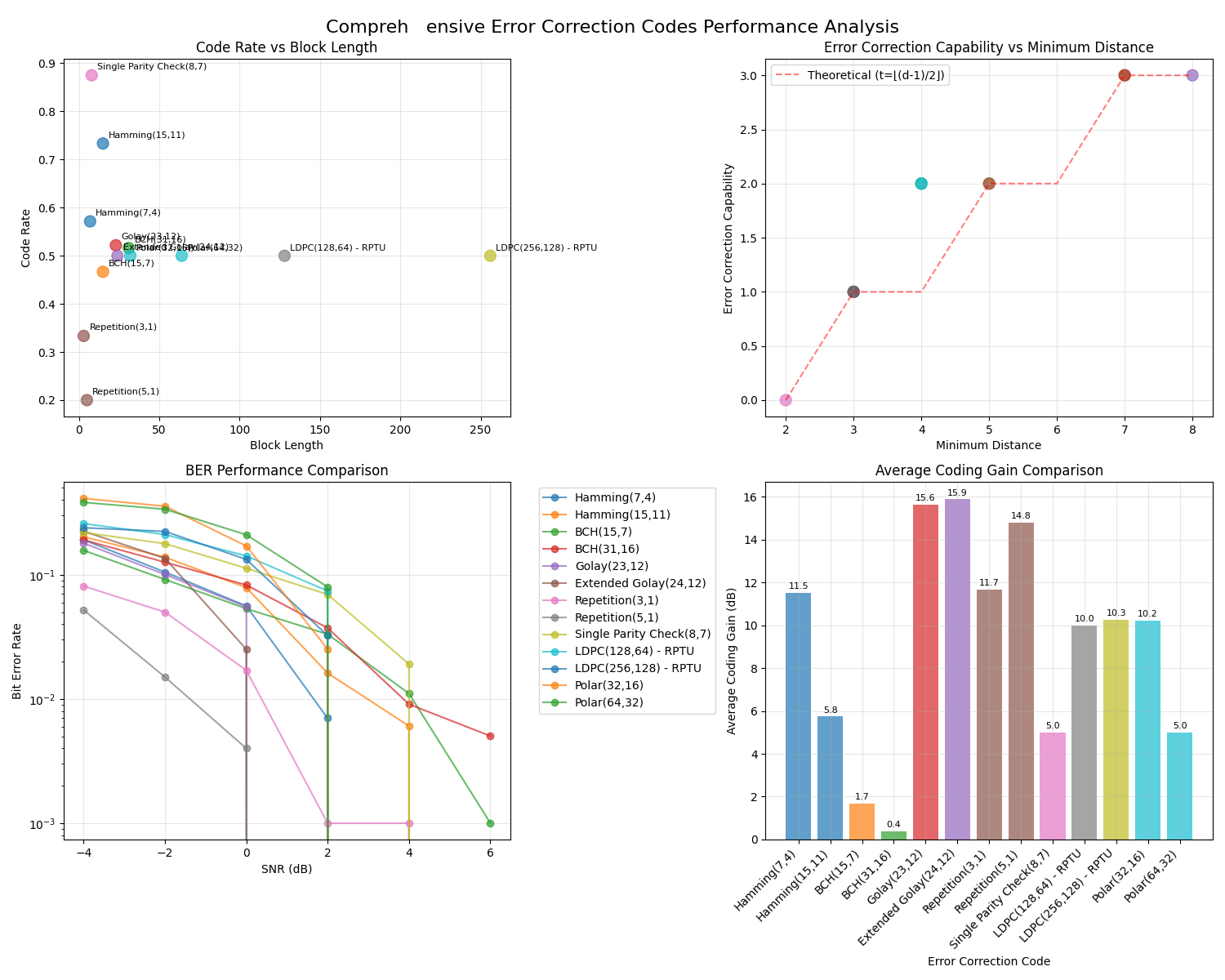
def visualize_ecc_performance(comprehensive_result):
"""Create comprehensive visualizations of ECC performance."""
if not comprehensive_result.metrics["success"]:
print("Comprehensive benchmark failed, cannot create visualizations")
return
configs = comprehensive_result.metrics["configurations"]
snr_results = comprehensive_result.metrics["snr_performance_results"]
# Create subplots for different aspects
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
fig.suptitle("Compreh ensive Error Correction Codes Performance Analysis", fontsize=16)
# 1. Code Rate vs Block Length
ax1 = axes[0, 0]
block_lengths = [c["block_length"] for c in configs]
code_rates = [c["code_rate"] for c in configs]
names = [c["name"] for c in configs]
ax1.scatter(block_lengths, code_rates, s=100, alpha=0.7, c=range(len(configs)), cmap="tab10")
ax1.set_xlabel("Block Length")
ax1.set_ylabel("Code Rate")
ax1.set_title("Code Rate vs Block Length")
ax1.grid(True, alpha=0.3)
# Add labels
for i, name in enumerate(names):
ax1.annotate(name, (block_lengths[i], code_rates[i]), xytext=(5, 5), textcoords="offset points", fontsize=8)
# 2. Error Correction Capability vs Minimum Distance
ax2 = axes[0, 1]
min_distances = [c["min_distance"] for c in configs]
error_capabilities = [c["error_correction_capability"] for c in configs]
ax2.scatter(min_distances, error_capabilities, s=100, alpha=0.7, c=range(len(configs)), cmap="tab10")
ax2.set_xlabel("Minimum Distance")
ax2.set_ylabel("Error Correction Capability")
ax2.set_title("Error Correction Capability vs Minimum Distance")
ax2.grid(True, alpha=0.3)
# Add theoretical line (t = floor((d-1)/2))
d_theory = np.arange(2, max(min_distances) + 1)
t_theory = np.floor((d_theory - 1) / 2)
ax2.plot(d_theory, t_theory, "r--", alpha=0.5, label="Theoretical (t=⌊(d-1)/2⌋)")
ax2.legend()
# 3. BER Performance Comparison
ax3 = axes[1, 0]
snr_range = list(range(-4, 8, 2)) # From config
for name in names:
if name in snr_results and snr_results[name]["success"]:
ber_coded = snr_results[name]["ber_coded"]
if len(ber_coded) == len(snr_range):
ax3.semilogy(snr_range, ber_coded, "o-", label=name, alpha=0.7)
ax3.set_xlabel("SNR (dB)")
ax3.set_ylabel("Bit Error Rate")
ax3.set_title("BER Performance Comparison")
ax3.grid(True, alpha=0.3)
ax3.legend(bbox_to_anchor=(1.05, 1), loc="upper left")
# 4. Coding Gain Analysis
ax4 = axes[1, 1]
avg_gains = []
for name in names:
if name in snr_results and snr_results[name]["success"]:
gains = snr_results[name]["coding_gain"]
finite_gains = [g for g in gains if np.isfinite(g)]
avg_gain = np.mean(finite_gains) if finite_gains else 0
avg_gains.append(avg_gain)
else:
avg_gains.append(0)
bars = ax4.bar(range(len(names)), avg_gains, alpha=0.7, color=plt.cm.tab10(np.linspace(0, 1, len(names))))
ax4.set_xlabel("Error Correction Code")
ax4.set_ylabel("Average Coding Gain (dB)")
ax4.set_title("Average Coding Gain Comparison")
ax4.set_xticks(range(len(names)))
ax4.set_xticklabels(names, rotation=45, ha="right")
ax4.grid(True, alpha=0.3)
# Add value labels on bars
for i, (bar, gain) in enumerate(zip(bars, avg_gains)):
ax4.text(bar.get_x() + bar.get_width() / 2, bar.get_height() + 0.1, f"{gain:.1f}", ha="center", va="bottom", fontsize=8)
plt.tight_layout()
plt.show()
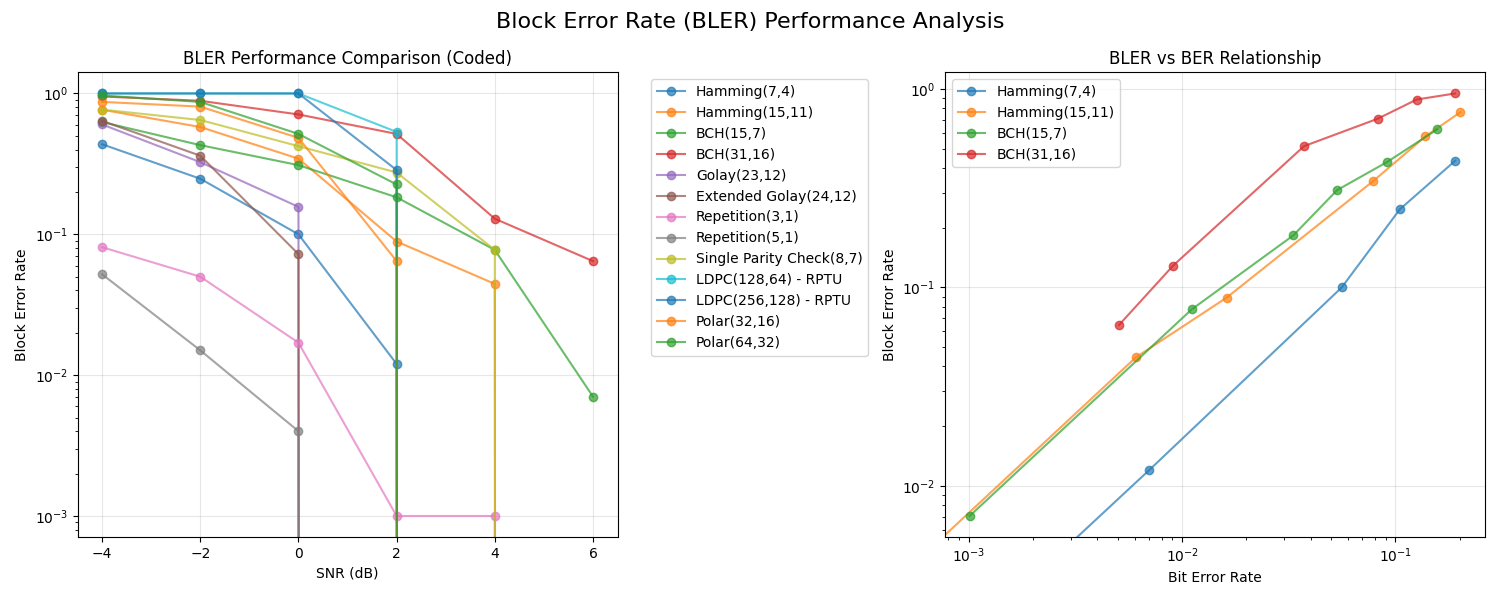
# Create additional figure for BLER comparison
fig2, (ax5, ax6) = plt.subplots(1, 2, figsize=(15, 6))
fig2.suptitle("Block Error Rate (BLER) Performance Analysis", fontsize=16)
# 5. BLER Performance Comparison
for name in names:
if name in snr_results and snr_results[name]["success"] and "bler_coded" in snr_results[name]:
bler_coded = snr_results[name]["bler_coded"]
if len(bler_coded) == len(snr_range):
ax5.semilogy(snr_range, bler_coded, "o-", label=name, alpha=0.7)
ax5.set_xlabel("SNR (dB)")
ax5.set_ylabel("Block Error Rate")
ax5.set_title("BLER Performance Comparison (Coded)")
ax5.grid(True, alpha=0.3)
ax5.legend(bbox_to_anchor=(1.05, 1), loc="upper left")
# 6. BLER vs BER Comparison for selected codes
selected_codes = names[:4] # Show first 4 codes to avoid clutter
for name in selected_codes:
if name in snr_results and snr_results[name]["success"]:
ber_coded = snr_results[name].get("ber_coded", [])
bler_coded = snr_results[name].get("bler_coded", [])
if len(ber_coded) == len(snr_range) and len(bler_coded) == len(snr_range):
ax6.loglog(ber_coded, bler_coded, "o-", label=f"{name}", alpha=0.7)
ax6.set_xlabel("Bit Error Rate")
ax6.set_ylabel("Block Error Rate")
ax6.set_title("BLER vs BER Relationship")
ax6.grid(True, alpha=0.3)
ax6.legend()
plt.tight_layout()
plt.show()
# Print summary statistics
print("\n" + "=" * 60)
print("COMPREHENSIVE ECC BENCHMARK SUMMARY")
print("=" * 60)
for i, config in enumerate(configs):
name = config["name"]
print(f"\n{name}:")
print(f" Block Length: {config['block_length']}")
print(f" Information Length: {config['info_length']}")
print(f" Code Rate: {config['code_rate']:.3f}")
print(f" Minimum Distance: {config['min_distance']}")
print(f" Error Correction Capability: {config['error_correction_capability']}")
if name in snr_results and snr_results[name]["success"]:
avg_gain = avg_gains[i]
print(f" Average Coding Gain: {avg_gain:.2f} dB")
# Best BER achieved
ber_coded = snr_results[name]["ber_coded"]
if ber_coded:
best_ber = min([b for b in ber_coded if b > 0])
print(f" Best BER Achieved: {best_ber:.2e}")
else:
print(" SNR evaluation failed")
Creating ECC Benchmark Suite
Let’s create a benchmark suite for systematic evaluation.
def create_ecc_benchmark_suite():
"""Create a comprehensive ECC benchmark suite."""
print("Creating ECC Benchmark Suite...")
# Create benchmark suite
suite = BenchmarkSuite(name="ECC Comprehensive Evaluation", description="Comprehensive evaluation of error correction codes")
# Add individual benchmarks
suite.add_benchmark(create_benchmark("comprehensive_ecc"))
# Add channel coding benchmarks for different configurations
ecc_configs = [
("repetition", 1 / 3, "Repetition Code (Rate 1/3)"),
("repetition", 1 / 5, "Repetition Code (Rate 1/5)"),
]
for code_type, rate, description in ecc_configs:
suite.add_benchmark(create_benchmark("channel_coding", code_type=code_type, code_rate=rate))
# Configure suite
config = BenchmarkConfig(name="ecc_suite_evaluation", snr_range=list(range(-4, 10, 2)), num_trials=1000, verbose=True)
config.update(num_bits=1000)
return suite, config
Running the Complete ECC Evaluation
Let’s run the complete evaluation pipeline.
def run_complete_ecc_evaluation():
"""Run the complete ECC evaluation pipeline."""
print("Starting Complete ECC Evaluation Pipeline...")
# Run individual benchmarks
print("\n" + "=" * 50)
print("PHASE 1: Individual ECC Benchmarks")
print("=" * 50)
individual_results = run_individual_ecc_benchmarks()
# Run comprehensive benchmark
print("\n" + "=" * 50)
print("PHASE 2: Comprehensive ECC Benchmark")
print("=" * 50)
comprehensive_result = run_comprehensive_ecc_benchmark()
# Create visualizations
print("\n" + "=" * 50)
print("PHASE 3: Performance Visualization")
print("=" * 50)
visualize_ecc_performance(comprehensive_result)
# Run benchmark suite
print("\n" + "=" * 50)
print("PHASE 4: Benchmark Suite Evaluation")
print("=" * 50)
suite, config = create_ecc_benchmark_suite()
runner = StandardRunner(verbose=True)
suite_results = runner.run_suite(suite, **config.to_dict())
print(f"\nSuite completed with {len(suite_results)} benchmark results")
return {"individual_results": individual_results, "comprehensive_result": comprehensive_result, "suite_results": suite_results}
Main Execution
Run the complete ECC evaluation when this script is executed.
if __name__ == "__main__":
# Set up matplotlib for better plots
plt.style.use("default")
plt.rcParams["figure.figsize"] = (12, 8)
plt.rcParams["font.size"] = 10
# Run complete evaluation
all_results = run_complete_ecc_evaluation()
print("\n" + "=" * 60)
print("ECC COMPREHENSIVE BENCHMARK COMPLETED SUCCESSFULLY!")
print("=" * 60)
print("\nResults Summary:")
print(f"- Individual benchmarks: {len(all_results['individual_results'])}")
print(f"- Comprehensive evaluation: {'✓' if all_results['comprehensive_result'].metrics['success'] else '✗'}")
print(f"- Suite benchmarks: {len(all_results['suite_results'])}")
# Save results
results_dir = Path("./ecc_benchmark_results")
results_dir.mkdir(exist_ok=True)
# Save comprehensive results
all_results["comprehensive_result"].save(results_dir / "comprehensive_ecc_results.json")
print(f"\nResults saved to: {results_dir}")
print("\nFor more examples, see the Kaira documentation at: https://kaira.readthedocs.io/")
Starting Complete ECC Evaluation Pipeline...
==================================================
PHASE 1: Individual ECC Benchmarks
==================================================
Running Individual ECC Benchmarks...
Testing Repetition Code (Rate 1/3)...
Average coding gain: 5.76 dB
Testing Repetition Code (Rate 1/5)...
Average coding gain: 8.89 dB
Testing Repetition Code (Rate 1/7)...
Average coding gain: 10.60 dB
==================================================
PHASE 2: Comprehensive ECC Benchmark
==================================================
Running Comprehensive ECC Benchmark...
Running benchmark: Comprehensive ECC Benchmark
Running comprehensive ECC benchmark with 13 configurations...
Evaluating Hamming(7,4) (1/13)...
Evaluating Hamming(15,11) (2/13)...
Evaluating BCH(15,7) (3/13)...
Evaluating BCH(31,16) (4/13)...
Evaluating Golay(23,12) (5/13)...
Evaluating Extended Golay(24,12) (6/13)...
Evaluating Repetition(3,1) (7/13)...
Evaluating Repetition(5,1) (8/13)...
Evaluating Single Parity Check(8,7) (9/13)...
Evaluating LDPC(128,64) - RPTU (10/13)...
Loading LDPC code from RPTU database...
Michael Helmling, Stefan Scholl, Florian Gensheimer, Tobias Dietz, Kira Kraft, Oliver Griebel, Stefan Ruzika, and Norbert Wehn. Database of Channel Codes and ML Simulation Results. rptu.de/channel-codes, 2025.
------------------------------------
Using default rptu_standart='ccsds' for (code_length=128, code_dimension=64).
Loading LDPC code from RPTU database...
Michael Helmling, Stefan Scholl, Florian Gensheimer, Tobias Dietz, Kira Kraft, Oliver Griebel, Stefan Ruzika, and Norbert Wehn. Database of Channel Codes and ML Simulation Results. rptu.de/channel-codes, 2025.
------------------------------------
Using default rptu_standart='ccsds' for (code_length=128, code_dimension=64).
Evaluating LDPC(256,128) - RPTU (11/13)...
Loading LDPC code from RPTU database...
Michael Helmling, Stefan Scholl, Florian Gensheimer, Tobias Dietz, Kira Kraft, Oliver Griebel, Stefan Ruzika, and Norbert Wehn. Database of Channel Codes and ML Simulation Results. rptu.de/channel-codes, 2025.
------------------------------------
Using default rptu_standart='ccsds' for (code_length=256, code_dimension=128).
Loading LDPC code from RPTU database...
Michael Helmling, Stefan Scholl, Florian Gensheimer, Tobias Dietz, Kira Kraft, Oliver Griebel, Stefan Ruzika, and Norbert Wehn. Database of Channel Codes and ML Simulation Results. rptu.de/channel-codes, 2025.
------------------------------------
Using default rptu_standart='ccsds' for (code_length=256, code_dimension=128).
Evaluating Polar(32,16) (12/13)...
Loading rank polar indices as defined in 5G standard...
Loading rank polar indices as defined in 5G standard...
Evaluating Polar(64,32) (13/13)...
Loading rank polar indices as defined in 5G standard...
Loading rank polar indices as defined in 5G standard...
✓ Completed in 49.15s
==================================================
PHASE 3: Performance Visualization
==================================================
============================================================
COMPREHENSIVE ECC BENCHMARK SUMMARY
============================================================
Hamming(7,4):
Block Length: 7
Information Length: 4
Code Rate: 0.571
Minimum Distance: 3
Error Correction Capability: 1
Average Coding Gain: 11.53 dB
Best BER Achieved: 7.00e-03
Hamming(15,11):
Block Length: 15
Information Length: 11
Code Rate: 0.733
Minimum Distance: 3
Error Correction Capability: 1
Average Coding Gain: 5.75 dB
Best BER Achieved: 6.06e-03
BCH(15,7):
Block Length: 15
Information Length: 7
Code Rate: 0.467
Minimum Distance: 5
Error Correction Capability: 2
Average Coding Gain: 1.69 dB
Best BER Achieved: 1.01e-03
BCH(31,16):
Block Length: 31
Information Length: 16
Code Rate: 0.516
Minimum Distance: 7
Error Correction Capability: 3
Average Coding Gain: 0.38 dB
Best BER Achieved: 5.04e-03
Golay(23,12):
Block Length: 23
Information Length: 12
Code Rate: 0.522
Minimum Distance: 7
Error Correction Capability: 3
Average Coding Gain: 15.64 dB
Best BER Achieved: 5.52e-02
Extended Golay(24,12):
Block Length: 24
Information Length: 12
Code Rate: 0.500
Minimum Distance: 8
Error Correction Capability: 3
Average Coding Gain: 15.89 dB
Best BER Achieved: 2.51e-02
Repetition(3,1):
Block Length: 3
Information Length: 1
Code Rate: 0.333
Minimum Distance: 3
Error Correction Capability: 1
Average Coding Gain: 11.68 dB
Best BER Achieved: 1.00e-03
Repetition(5,1):
Block Length: 5
Information Length: 1
Code Rate: 0.200
Minimum Distance: 5
Error Correction Capability: 2
Average Coding Gain: 14.80 dB
Best BER Achieved: 4.00e-03
Single Parity Check(8,7):
Block Length: 8
Information Length: 7
Code Rate: 0.875
Minimum Distance: 2
Error Correction Capability: 0
Average Coding Gain: 5.00 dB
Best BER Achieved: 1.91e-02
LDPC(128,64) - RPTU:
Block Length: 128
Information Length: 64
Code Rate: 0.500
Minimum Distance: 4
Error Correction Capability: 2
Average Coding Gain: 10.00 dB
Best BER Achieved: 7.40e-02
LDPC(256,128) - RPTU:
Block Length: 256
Information Length: 128
Code Rate: 0.500
Minimum Distance: 4
Error Correction Capability: 2
Average Coding Gain: 10.27 dB
Best BER Achieved: 3.24e-02
Polar(32,16):
Block Length: 32
Information Length: 16
Code Rate: 0.500
Minimum Distance: 4
Error Correction Capability: 2
Average Coding Gain: 10.22 dB
Best BER Achieved: 2.52e-02
Polar(64,32):
Block Length: 64
Information Length: 32
Code Rate: 0.500
Minimum Distance: 4
Error Correction Capability: 2
Average Coding Gain: 5.00 dB
Best BER Achieved: 7.96e-02
==================================================
PHASE 4: Benchmark Suite Evaluation
==================================================
Creating ECC Benchmark Suite...
Running benchmark suite: ECC Comprehensive Evaluation
3 benchmarks to run
[1/3] Comprehensive ECC Benchmark
Running benchmark: Comprehensive ECC Benchmark
Running comprehensive ECC benchmark with 13 configurations...
Evaluating Hamming(7,4) (1/13)...
Evaluating Hamming(15,11) (2/13)...
Evaluating BCH(15,7) (3/13)...
Evaluating BCH(31,16) (4/13)...
Evaluating Golay(23,12) (5/13)...
Evaluating Extended Golay(24,12) (6/13)...
Evaluating Repetition(3,1) (7/13)...
Evaluating Repetition(5,1) (8/13)...
Evaluating Single Parity Check(8,7) (9/13)...
Evaluating LDPC(128,64) - RPTU (10/13)...
Loading LDPC code from RPTU database...
Michael Helmling, Stefan Scholl, Florian Gensheimer, Tobias Dietz, Kira Kraft, Oliver Griebel, Stefan Ruzika, and Norbert Wehn. Database of Channel Codes and ML Simulation Results. rptu.de/channel-codes, 2025.
------------------------------------
Using default rptu_standart='ccsds' for (code_length=128, code_dimension=64).
Loading LDPC code from RPTU database...
Michael Helmling, Stefan Scholl, Florian Gensheimer, Tobias Dietz, Kira Kraft, Oliver Griebel, Stefan Ruzika, and Norbert Wehn. Database of Channel Codes and ML Simulation Results. rptu.de/channel-codes, 2025.
------------------------------------
Using default rptu_standart='ccsds' for (code_length=128, code_dimension=64).
Evaluating LDPC(256,128) - RPTU (11/13)...
Loading LDPC code from RPTU database...
Michael Helmling, Stefan Scholl, Florian Gensheimer, Tobias Dietz, Kira Kraft, Oliver Griebel, Stefan Ruzika, and Norbert Wehn. Database of Channel Codes and ML Simulation Results. rptu.de/channel-codes, 2025.
------------------------------------
Using default rptu_standart='ccsds' for (code_length=256, code_dimension=128).
Loading LDPC code from RPTU database...
Michael Helmling, Stefan Scholl, Florian Gensheimer, Tobias Dietz, Kira Kraft, Oliver Griebel, Stefan Ruzika, and Norbert Wehn. Database of Channel Codes and ML Simulation Results. rptu.de/channel-codes, 2025.
------------------------------------
Using default rptu_standart='ccsds' for (code_length=256, code_dimension=128).
Evaluating Polar(32,16) (12/13)...
Loading rank polar indices as defined in 5G standard...
Loading rank polar indices as defined in 5G standard...
Evaluating Polar(64,32) (13/13)...
Loading rank polar indices as defined in 5G standard...
Loading rank polar indices as defined in 5G standard...
✓ Completed in 394.01s
[2/3] Channel Coding (repetition, R=0.3333333333333333)
Running benchmark: Channel Coding (repetition, R=0.3333333333333333)
✓ Completed in 0.02s
[3/3] Channel Coding (repetition, R=0.2)
Running benchmark: Channel Coding (repetition, R=0.2)
✓ Completed in 0.02s
Suite completed with 3 benchmark results
============================================================
ECC COMPREHENSIVE BENCHMARK COMPLETED SUCCESSFULLY!
============================================================
Results Summary:
- Individual benchmarks: 3
- Comprehensive evaluation: ✓
- Suite benchmarks: 3
Results saved to: ecc_benchmark_results
For more examples, see the Kaira documentation at: https://kaira.readthedocs.io/
Total running time of the script: (7 minutes 24.409 seconds)