Note
Go to the end to download the full example code. or to run this example in your browser via Binder
Audio Losses for Speech and Music Quality
This example demonstrates the various audio losses available in kaira for assessing audio quality and training audio-based models.
We’ll cover: - STFT Loss (Short-Time Fourier Transform) - Multi-Resolution STFT Loss - Mel-Spectrogram Loss
First, let’s import the necessary modules
import torch
import torch.nn as nn
import torchaudio
from kaira.losses import LossRegistry
Create sample audio data - we’ll generate a simple signal with harmonics
def create_sample_audio():
"""Create a sample audio signal and its degraded version."""
# Create a sample audio signal (sine wave)
duration = 3 # seconds
sr = 22050 # sample rate
t = np.linspace(0, duration, int(sr * duration))
original = np.sin(2 * np.pi * 440 * t) # 440 Hz tone
# Create degraded version with noise
noise = np.random.normal(0, 0.1, original.shape)
degraded = original + noise
# Convert to torch tensors and ensure contiguous memory layout
original = torch.from_numpy(original.copy()).float().unsqueeze(0)
degraded = torch.from_numpy(degraded.copy()).float().unsqueeze(0)
return original, degraded, sr
# Create sample audio
original, degraded, sr = create_sample_audio()
Let’s visualize our sample audio signals
plt.figure(figsize=(12, 4))
plt.subplot(211)
plt.plot(original.squeeze().numpy())
plt.title("Original Audio")
plt.xlabel("Sample")
plt.ylabel("Amplitude")
plt.subplot(212)
plt.plot(degraded.squeeze().numpy())
plt.title("Degraded Audio")
plt.xlabel("Sample")
plt.ylabel("Amplitude")
plt.tight_layout()
plt.show()
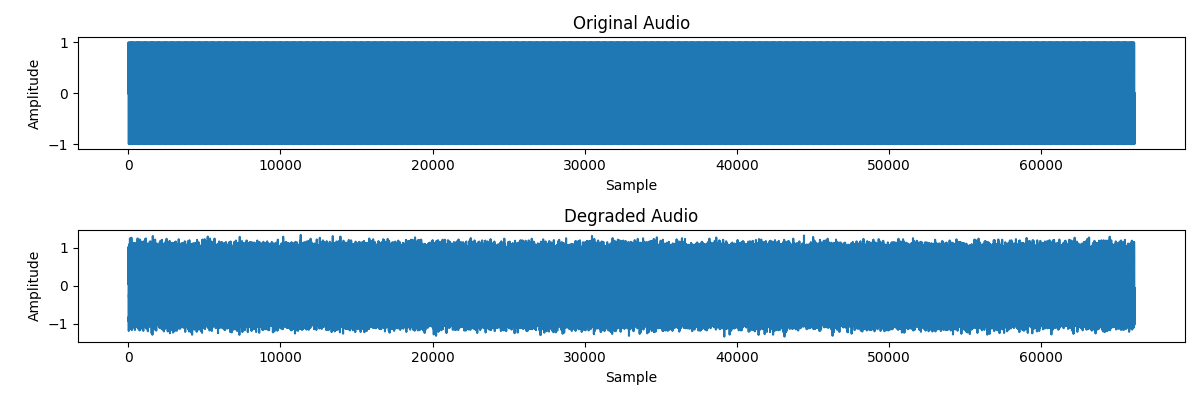
Now let’s compute different audio losses
# STFT Loss
stft_loss = LossRegistry.create("stftloss", fft_size=1024, hop_size=256, win_length=1024)
stft_value = stft_loss(degraded, original).item()
print(f"STFT Loss: {stft_value:.4f}")
# Multi-Resolution STFT Loss
multi_res_stft_loss = LossRegistry.create("multiresolutionstftloss", fft_sizes=[512, 1024, 2048], hop_sizes=[128, 256, 512], win_lengths=[512, 1024, 2048])
multi_res_value = multi_res_stft_loss(degraded, original).item()
print(f"Multi-Resolution STFT Loss: {multi_res_value:.4f}")
# Mel-Spectrogram Loss
mel_loss = LossRegistry.create("melspectrogramloss", sample_rate=sr, n_fft=1024, hop_length=256, n_mels=80)
mel_value = mel_loss(degraded, original).item()
print(f"Mel-Spectrogram Loss: {mel_value:.4f}")
STFT Loss: 11.2232
Multi-Resolution STFT Loss: 11.3260
Mel-Spectrogram Loss: 13.6254
Let’s visualize the spectrograms to understand what these losses are comparing
def plot_spectrogram(waveform, sample_rate, title):
"""Plot the spectrogram of an audio waveform.
Args:
waveform (torch.Tensor): Input audio waveform tensor
sample_rate (int): Sampling rate of the audio in Hz
title (str): Title for the spectrogram plot
"""
spectrogram = torchaudio.transforms.Spectrogram(
n_fft=1024,
hop_length=256,
)(waveform)
spec_db = 20 * torch.log10(torch.clamp(spectrogram, min=1e-5))
plt.imshow(spec_db.squeeze().numpy(), aspect="auto", origin="lower")
plt.colorbar(format="%+2.0f dB")
plt.title(title)
plt.xlabel("Time Frame")
plt.ylabel("Frequency Bin")
plt.figure(figsize=(12, 8))
plt.subplot(211)
plot_spectrogram(original, sr, "Original Spectrogram")
plt.subplot(212)
plot_spectrogram(degraded, sr, "Degraded Spectrogram")
plt.tight_layout()
plt.show()
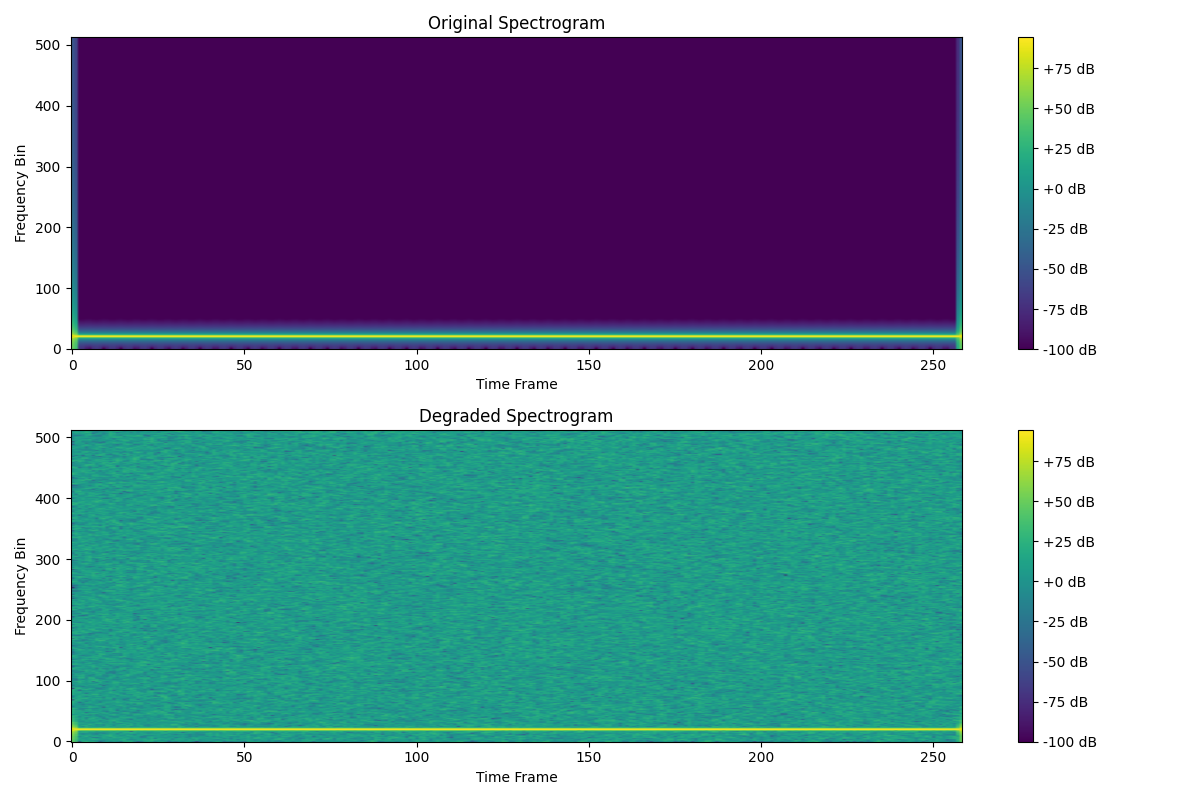
Let’s explore how different losses respond to various types of audio degradation
def apply_audio_degradation(signal, degradation_type, param):
"""Apply different types of audio degradation."""
if degradation_type == "noise":
return signal + torch.randn_like(signal) * param
elif degradation_type == "lowpass":
# Simple FIR lowpass filter
kernel_size = int(param)
if kernel_size % 2 == 0:
kernel_size += 1
kernel = torch.ones(1, 1, kernel_size) / kernel_size
return nn.functional.conv1d(signal.unsqueeze(1), kernel, padding=kernel_size // 2).squeeze(1)
return signal
# Create a range of degradation parameters
noise_levels = np.linspace(0, 0.5, 10)
filter_sizes = np.arange(1, 20, 2)
# Store results
noise_results: Dict[str, List[float]] = {"stft": [], "multi_res_stft": [], "mel": []}
filter_results: Dict[str, List[float]] = {"stft": [], "multi_res_stft": [], "mel": []}
# Compute losses for different noise levels
for noise in noise_levels:
noisy = apply_audio_degradation(original, "noise", noise)
noise_results["stft"].append(stft_loss(noisy, original).item())
noise_results["multi_res_stft"].append(multi_res_stft_loss(noisy, original).item())
noise_results["mel"].append(mel_loss(noisy, original).item())
# Compute losses for different filter sizes
for size in filter_sizes:
filtered = apply_audio_degradation(original, "lowpass", size)
filter_results["stft"].append(stft_loss(filtered, original).item())
filter_results["multi_res_stft"].append(multi_res_stft_loss(filtered, original).item())
filter_results["mel"].append(mel_loss(filtered, original).item())
Plot the results
plt.figure(figsize=(12, 5))
plt.subplot(121)
plt.plot(noise_levels, noise_results["stft"], label="STFT Loss")
plt.plot(noise_levels, noise_results["multi_res_stft"], label="Multi-Res STFT Loss")
plt.plot(noise_levels, noise_results["mel"], label="Mel-Spec Loss")
plt.xlabel("Noise Level (σ)")
plt.ylabel("Loss Value")
plt.title("Loss Response to Additive Noise")
plt.legend()
plt.subplot(122)
plt.plot(filter_sizes, filter_results["stft"], label="STFT Loss")
plt.plot(filter_sizes, filter_results["multi_res_stft"], label="Multi-Res STFT Loss")
plt.plot(filter_sizes, filter_results["mel"], label="Mel-Spec Loss")
plt.xlabel("Filter Size")
plt.ylabel("Loss Value")
plt.title("Loss Response to Low-Pass Filtering")
plt.legend()
plt.tight_layout()
plt.show()
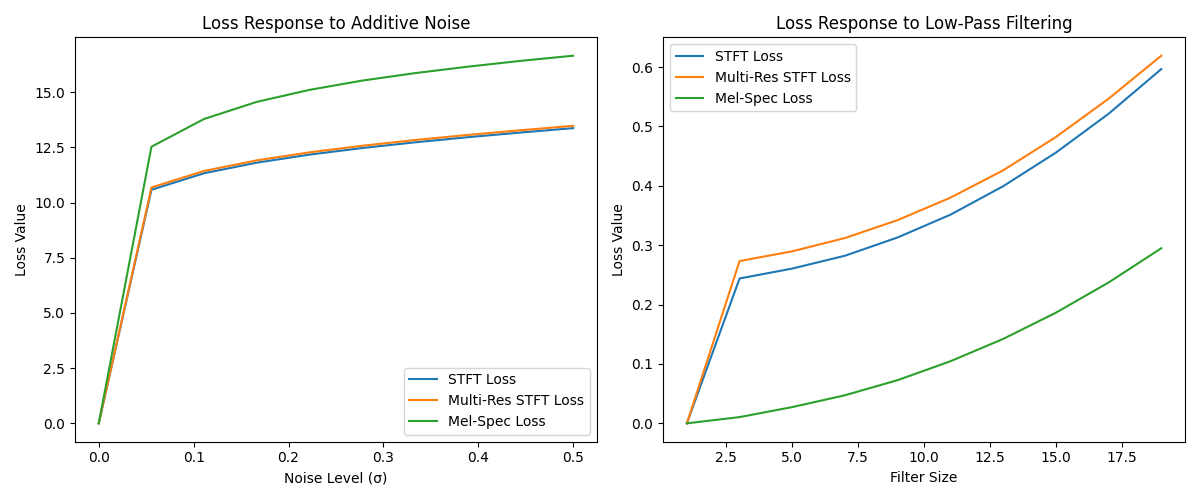
This example demonstrates how different audio losses capture various aspects of audio quality. The STFT loss captures time-frequency characteristics, while multi-resolution STFT provides better coverage across different time and frequency scales. The Mel-spectrogram loss focuses on perceptually relevant frequency bands, making it particularly useful for speech and music applications.
Total running time of the script: (0 minutes 1.064 seconds)